AI/ML Security & Privacy Overview
This AI/ML Security & Privacy Laboratory provides educational resources and practical implementations of various attacks and defenses described in the CyBOK Security and Privacy of AI Knowledge Guide.
As machine learning systems become increasingly integrated into critical applications, understanding their security vulnerabilities is essential for building robust AI systems.
AI Security Landscape
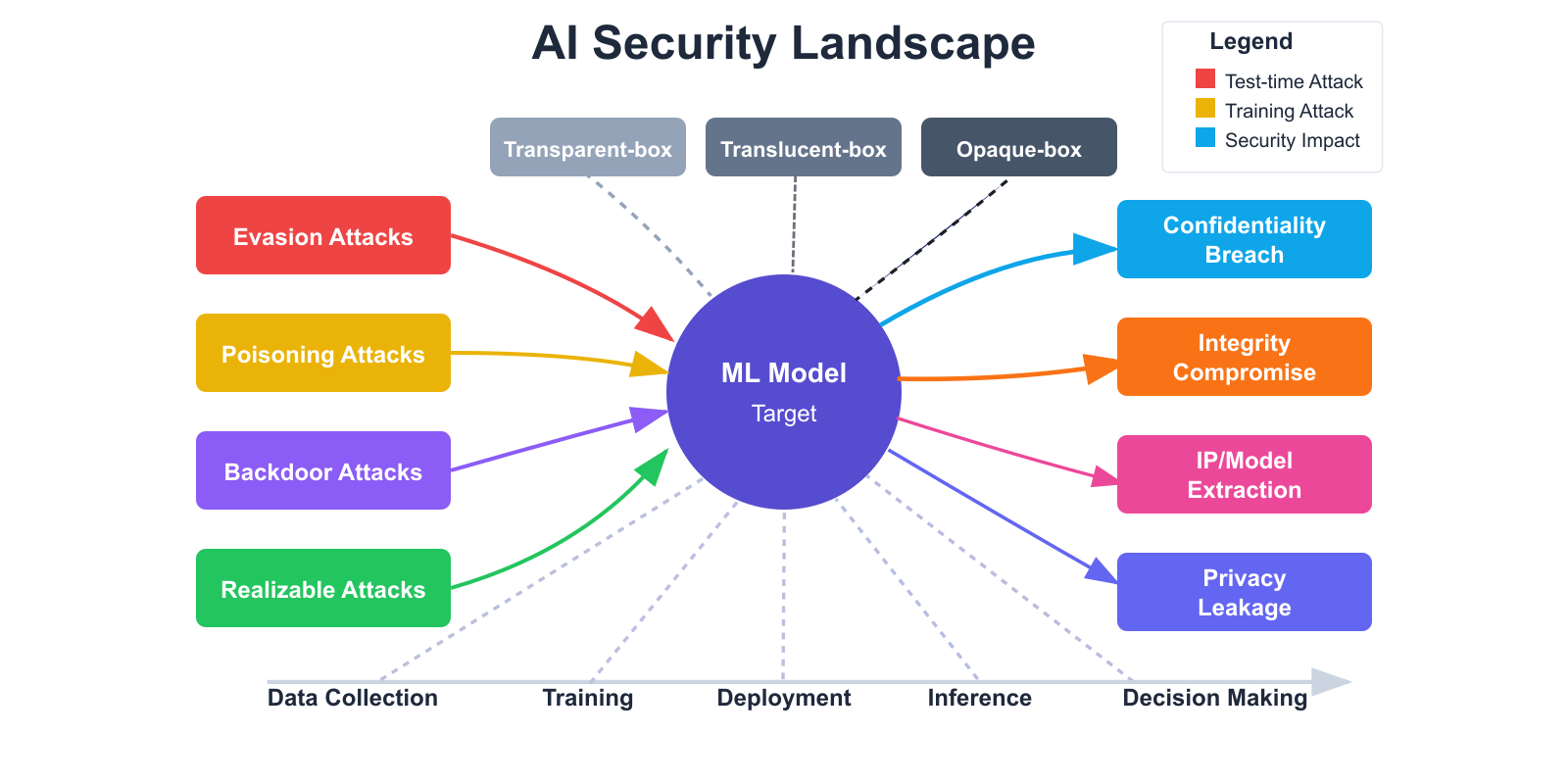
Figure 1.1: Overview of AI/ML security threats, attack vectors, and impact areas.
The AI/ML security landscape represents a complex ecosystem where various threats target machine learning models throughout their lifecycle. From data collection to deployment, each stage presents unique vulnerabilities that malicious actors can exploit. These threats don't just compromise the models themselves but can lead to serious consequences including confidentiality breaches, integrity compromises, intellectual property theft, and privacy violations.
Machine learning security is characterized by a diverse range of attack vectors, each with different techniques and impacts. Evasion attacks manipulate input data to cause misclassification without altering the model itself. Poisoning attacks contaminate training data to degrade performance or introduce specific vulnerabilities. Backdoor attacks embed hidden patterns that can be triggered later to cause targeted misbehavior, while realizable attacks focus on implementing adversarial techniques in real-world, physical environments despite practical constraints.
ML Pipeline Vulnerabilities
- Data Collection & Preprocessing
- Model Training & Validation
- Model Deployment & Serving
- Inference & Decision-making
Threat Actors & Capabilities
- Perfect-Knowledge (transparent-box)
- Partial-Knowledge (translucent-box)
- Zero-Knowledge (opaque-box)
- Active vs. Passive Attacks
Security concerns affect the entire machine learning pipeline. During data collection and preprocessing, adversaries might poison datasets or manipulate labels. The training phase is vulnerable to backdoor injections and hyperparameter manipulation. Once deployed, models face model theft attempts, adversarial examples, and exploitation of transfer learning weaknesses. Even at inference time, attackers can manipulate confidence scores, exploit decision boundaries, or generate misleading explanations.
The severity of these threats depends significantly on the attacker's knowledge and capabilities. Transparent-box attackers possess complete information about the model and its training, representing the most dangerous scenario. Translucent-box attackers have partial knowledge, while opaque-box attackers must rely on observations of the model's outputs. Understanding these threat models is crucial for implementing appropriate defense strategies that address realistic adversarial capabilities.
Environment Setup
We've prepared a simple Python script to help you set up the complete environment for AI/ML security testing. This script will create all necessary directories and install the required dependencies to ensure a seamless experience with the lab environment.
Setup Requirements
No special setup is needed beyond a basic Python installation and internet connection. The script will handle installing all required libraries and creating the necessary directory structure.
Setup Steps
- Download the
setup.shfile from the resources section below - Open a terminal or command prompt
- Navigate to the directory where you saved the script
- Run the script:
./setup.sh - Wait for the script to create directories and install dependencies
- then run
./start_lab.shto make laboratory dependencies setup - Begin exploring the AI/ML security testing environment!
Video Demonstration
Video demonstration of environment setup process
Need Help?
If you encounter any issues during setup, please check the troubleshooting guide or readme file in the Project Repository & Follow the Instructions carefully to ensure a smooth setup process.
Students:
The AI/ML Security & Privacy Lab offers a hands-on environment where you can delve into the critical security and privacy challenges of AI/ML. We encourage you to use this lab's materials to learn and explore real-world attacks, analyse and modify code, practice ethical hacking, detect vulnerabilities, and implement effective mitigations. By actively engaging with these materials, you will strengthen AI/ML models against threats and develop the expertise to secure future AI systems.
Educators:
The AI/ML Security & Privacy Lab provides a comprehensive set of code, images, and documents to enrich your AI/ML security and privacy curriculum. We encourage you to adapt these resources, e.g., by removing sections of code for students to complete or tailoring scenarios to your course needs—to create engaging lectures and lab sessions. By leveraging our practical, interactive materials, you will convey complex concepts more effectively and inspire students through hands-on learning. Please contact the project's lead if you have any questions and/or suggestions.
CyBOK © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence
http://www.nationalarchives.gov.uk/doc/open-government-licence.
When you use this information under the Open Government Licence, you should include the following attribution:
CyBOK Materials for AI for Security © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence:
http://www.nationalarchives.gov.uk/doc/open-government-licence.
Attack Types
Machine learning models are vulnerable to various types of attacks targeting different aspects of the ML pipeline. Below are the main categories of attacks implemented in our laboratory:
Evasion Attacks
Adversarial examples that cause misclassification at inference time.
Poisoning Attacks
Corrupting training data to degrade model performance.
Backdoor Attacks
Embedding hidden functionality triggered by specific patterns.
Realizable Attacks
Physical-world attacks that respect real-world constraints.
Model Stealing
Extracting model functionality or architecture through API access.
Privacy Attacks
Extracting sensitive information from models or training data.
Machine learning models, despite their impressive capabilities, are susceptible to a wide range of security threats that exploit different stages of the ML lifecycle. These attacks can compromise model integrity, confidentiality, and availability. In our laboratory, we have implemented and analyzed several such attacks to understand their impact and develop effective countermeasures. The primary categories of attacks include evasion attacks, which manipulate inputs at inference time to induce incorrect predictions; poisoning attacks, which tamper with training data to corrupt the learning process; and backdoor attacks, which insert hidden behaviors triggered by specific inputs. Other attack types include realizable attacks, which are constrained by physical-world feasibility; model stealing, where adversaries aim to replicate or reverse-engineer the model via exposed APIs; and privacy attacks, which attempt to extract sensitive training data or attributes. The following sections will elaborate on each of these attacks in greater detail, highlighting their mechanisms, implications, and potential defenses
CyBOK © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence
http://www.nationalarchives.gov.uk/doc/open-government-licence.
When you use this information under the Open Government Licence, you should include the following attribution:
CyBOK Materials for AI for Security © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence:
http://www.nationalarchives.gov.uk/doc/open-government-licence.
Demonstrations
Explore our video demonstrations showcasing various aspects of AI/ML security testing. Each video provides practical insights into the implementation and execution of different security techniques covered in this laboratory.
Lab Setup Demonstration
Step-by-step guide to setting up a complete AI/ML security testing laboratory with all required tools and configurations.
Attack Demonstration
Detailed walkthrough of evasion, poisoning, and backdoor attacks against machine learning models with practical examples.
Defense Demonstration
Implementation of defensive techniques including adversarial training, data sanitization, and differential privacy.
Environment Setup Demonstration
Configuring virtual environments, installing dependencies, and setting up development workflows for AI security testing.
AI-Driven Attack Demonstration
Showcasing advanced attacks that use AI to automatically generate adversarial examples and identify model vulnerabilities.
Pentesting Mitigtation Toolkit Demonstration
A tutorial demonstrating how to use the AI/ML Security Penetration Testing Toolkit for identifying, exploiting, and mitigating vulnerabilities in machine learning systems.
Evasion Attacks
Evasion attacks occur during the inference phase of machine learning models, where adversaries craft specialized inputs that force misclassification despite appearing nearly identical to legitimate data. These sophisticated attacks exploit vulnerabilities in the model's decision boundaries through optimized perturbations that remain typically imperceptible to human observers.
Evasion Attack Mechanism
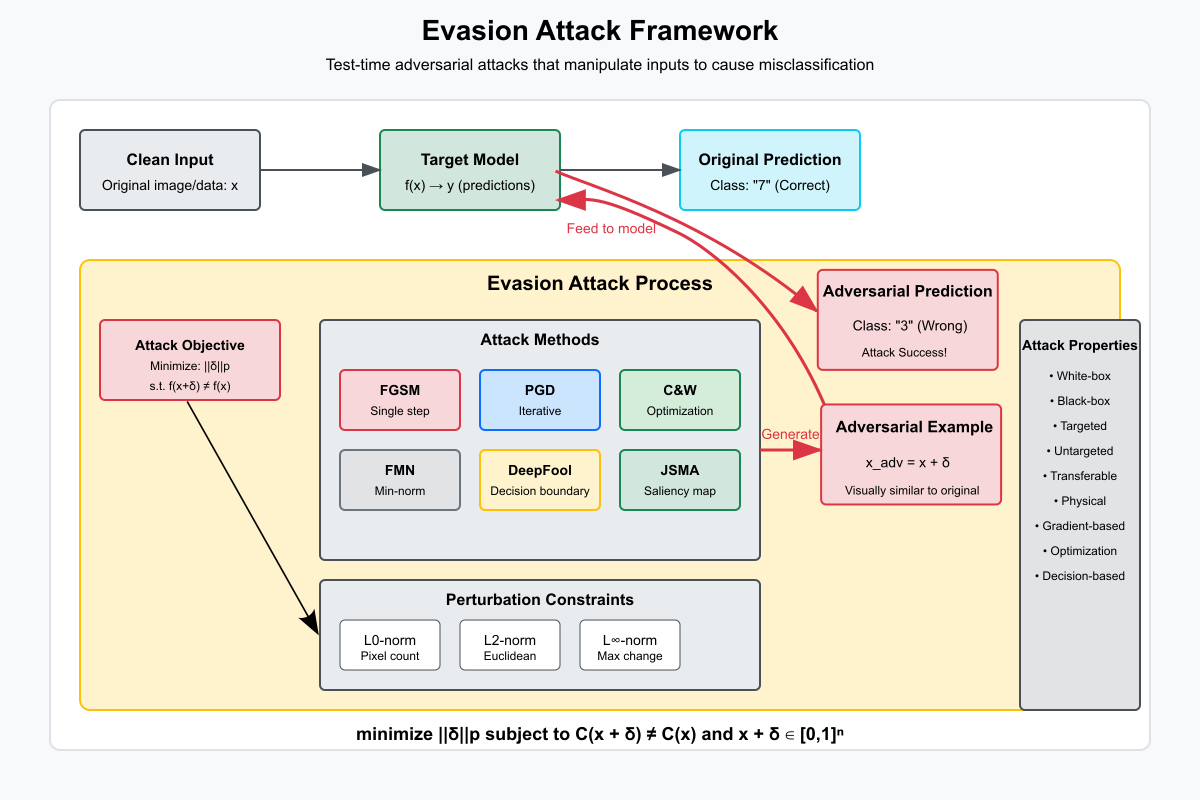
Figure 2.1.1: Adversarial perturbations shift inputs across decision boundaries, causing systematic misclassification while maintaining visual similarity.
Evasion attacks are a class of test-time adversarial attacks that occur during the inference phase of machine learning models. In these attacks, adversaries craft subtle but deliberately manipulated inputs—known as adversarial examples—that are designed to force the model into making incorrect predictions. What makes evasion attacks particularly dangerous is that these perturbations are often imperceptible to the human eye, yet they exploit vulnerabilities in the model’s learned decision boundaries. This manipulation effectively causes the input to cross into a different classification region, resulting in systematic misclassification without noticeably altering the data from a human perspective.
The general mechanism behind evasion attacks involves finding a small perturbation δ to the original input x such that the model's prediction f(x + δ) differs from f(x), while keeping the perturbation small enough to avoid detection. Attackers typically aim to minimize the size of δ using various norms—L0, L2, or L∞—to constrain the nature of the perturbation. Different attack strategies have emerged based on this core idea. Notable among them is the Fast Gradient Sign Method (FGSM), a fast and simple approach that perturbs the input in the direction of the gradient of the loss function. By adding ε·sign(∇ₓL), FGSM creates an adversarial example that is computationally cheap to generate but may produce noticeable perturbations.
Fast Gradient Sign Method (FGSM)
FGSM represents a groundbreaking single-step attack approach that calculates optimal perturbations by analyzing the gradient of the loss function. This method revolutionized adversarial machine learning by demonstrating that surprisingly simple mathematical operations could deceive even sophisticated deep learning models. The attack's elegance lies in its efficiency—computing the sign of the gradient determines the direction that maximally increases the model's error while the epsilon parameter controls perturbation magnitude.
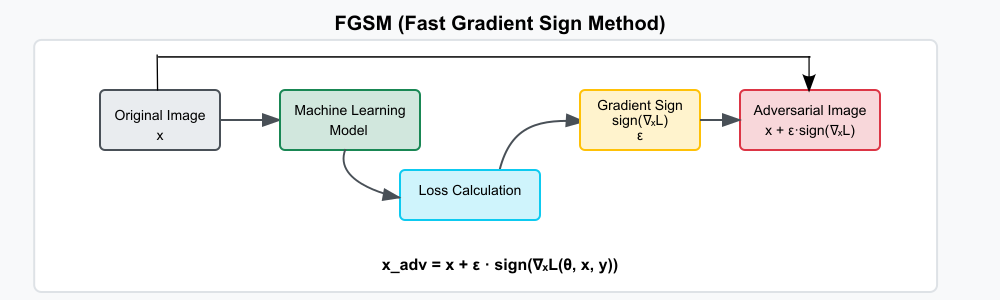
Figure 2.1.2: FGSM Attack Block Daigram..
Source: Created based on Goodfellow et al. (2015).
Projected Gradient Descent (PGD)
PGD extends FGSM into an iterative framework that progressively refines adversarial perturbations through multiple small steps. This sophisticated approach generates more robust adversarial examples by repeatedly applying gradient-based updates while projecting back onto a constrained perturbation space. The method balances between attack strength and perceptual similarity, making it particularly valuable for evaluating model robustness in realistic security scenarios.
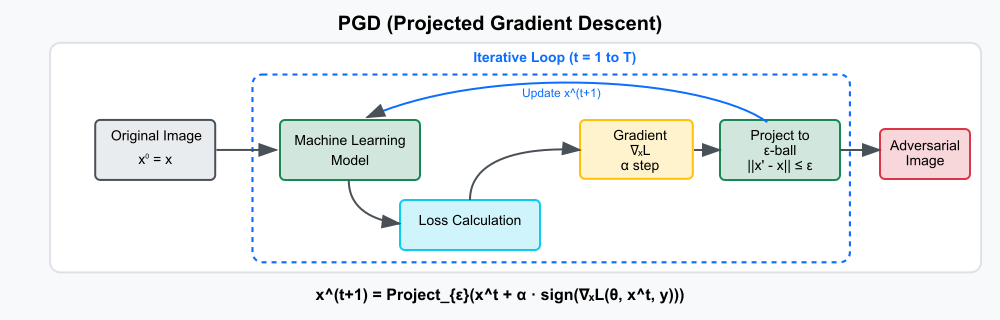
Figure 2.1.3: PGD Attack Block Daigram.
Source: Created based on Madry et al. (2018).
Building upon FGSM, the Projected Gradient Descent (PGD) attack adds iterative refinement to increase the strength and precision of the attack. PGD repeatedly applies small gradient-based updates and projects the resulting input back into an ε-ball around the original input to ensure the perturbation remains bounded. This iterative process generates more robust adversarial examples with better success rates while maintaining perceptual similarity.
Carlini & Wagner (C&W) Attack
The C&W attack represents the pinnacle of optimization-based adversarial techniques, formulating the perturbation problem as a sophisticated constrained optimization challenge: minimize ‖δ‖p + c · f(x + δ). This approach discovers minimal perturbations through advanced optimization algorithms, consistently bypassing common defense mechanisms by optimizing jointly for attack success and imperceptibility. The method's careful balance of objectives enables it to generate highly effective adversarial examples while minimizing detectability.
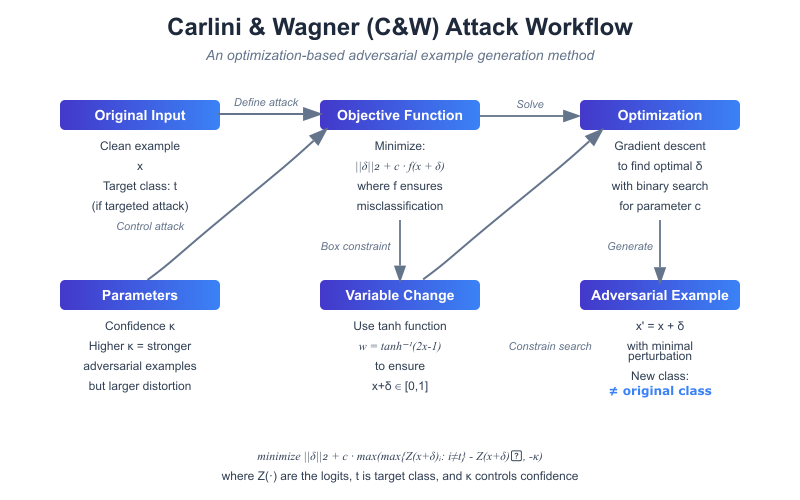
Figure 2.1.4: Carlini & Wagner (C&W) Attack Block Daigram.
Source: Created based on Carlini & Wagner (2017).
Comparative Analysis of Attack Methods
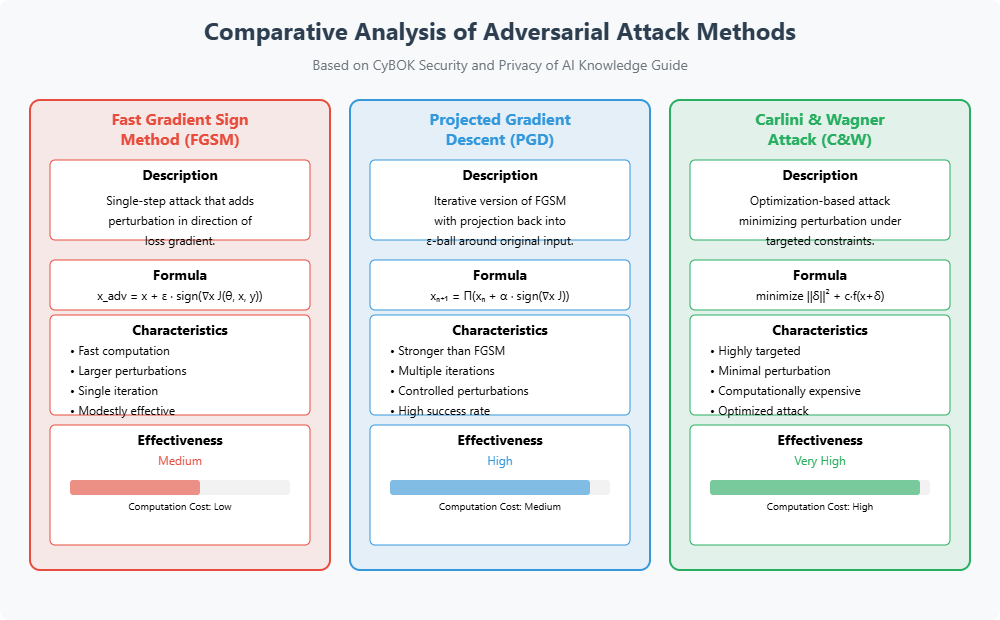
Figure 2.1.5: Visual comparison of adversarial examples generated by FGSM, PGD, and C&W attacks showing perturbation characteristics and effectiveness.
Source: Created based on Goodfellow et al. (2015); Madry et al. (2018); Carlini & Wagner (2017).
Comparative analysis of these attack methods highlights a trade-off between computational cost and attack effectiveness. FGSM is computationally efficient but less effective for well-defended models, making it suitable for quick testing. PGD offers a good balance, delivering stronger attacks at a moderate computational cost. In contrast, C&W delivers minimal and highly targeted perturbations at the cost of significant computation, making it ideal for high-stakes adversarial scenarios.
To understand and analyze evasion attacks, it’s crucial to grasp certain foundational concepts. The epsilon (ε) parameter controls the allowed perturbation magnitude, serving as a balance between stealth and strength. Decision boundaries in the model's feature space determine class regions, and adversarial perturbations aim to push inputs across these boundaries. Various Lp norms (L0, L2, L∞) define how perturbation size is measured, influencing how attacks are constructed and evaluated. Overall, evasion attacks expose the fragility of even state-of-the-art machine learning models and highlight the importance of developing more robust and secure AI systems.
Each attack method presents unique trade-offs between computational efficiency and attack effectiveness:
The fastest approach, executing in a single step with larger but more detectable perturbations. Ideal for quick vulnerability assessments and baseline testing.
Iterative refinement produces stronger attacks with medium-sized perturbations. Offers the best balance between computation time and attack success rate.
The most sophisticated method, generating minimal perturbations that evade most defenses. Computationally intensive but highly effective.
Advanced Concepts in Evasion Attacks
Understanding evasion attacks requires grasping several key concepts that define their behavior and effectiveness. The epsilon parameter determines the maximum allowed perturbation magnitude, essentially setting the boundary between imperceptibility and attack strength. Decision boundaries represent the high-dimensional surfaces that separate different classification regions—regions that adversarial examples attempt to cross with minimal deviation. Different Lp norms provide distinct ways to measure perturbation size, with L∞ constraining maximum pixel change while L2 measures overall energy. These mathematical foundations enable researchers to systematically study model vulnerabilities and develop more robust defenses.
Evasion Attack Hands-on Practicals
We've prepared comprehensive Jupyter Notebooks and practical code that will guide you through implementing various evasion attacks against machine learning models. These hands-on exercises will help you understand how adversaries can manipulate inputs to cause misclassification at inference time.
Setup Requirements
No special setup is needed beyond:
- Python 3.7+
- Jupyter Notebook
- TensorFlow/Keras
- NumPy, Matplotlib
- Adversarial Robustness Toolbox (ART)
All dependencies can be installed with Overview Setup at beginning
Available Evasion Attack Practicals
FGSM Attack
Learn how the Fast Gradient Sign Method creates adversarial examples with a single step.
Open Notebook →C&W Attack
Explore the Carlini & Wagner optimization-based attack for minimal perturbations.
Open Notebook →Getting Started
- Open the notebook of your choice (FGSM, PGD, or C&W)
- Follow the step-by-step instructions within the notebook
- Run the code cells in sequence to see the attack in action
- Observe the model behavior before and after the adversarial attack
- Modify parameters (optional) to see how they affect attack success rate
- Visualize the results using the provided plotting functions
Video Demonstration
Demonstration of FGSM attack against an MNIST digit classifier
Resources
Additional Resources
CyBOK © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence
http://www.nationalarchives.gov.uk/doc/open-government-licence.
When you use this information under the Open Government Licence, you should include the following attribution:
CyBOK Materials for AI for Security © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence:
http://www.nationalarchives.gov.uk/doc/open-government-licence.
Poisoning Attacks
Poisoning attacks occur during the training phase, where an adversary manipulates the training data to influence the learning process. This can degrade the model's performance on all inputs or on specific classes.
Poisoning Attack Mechanism
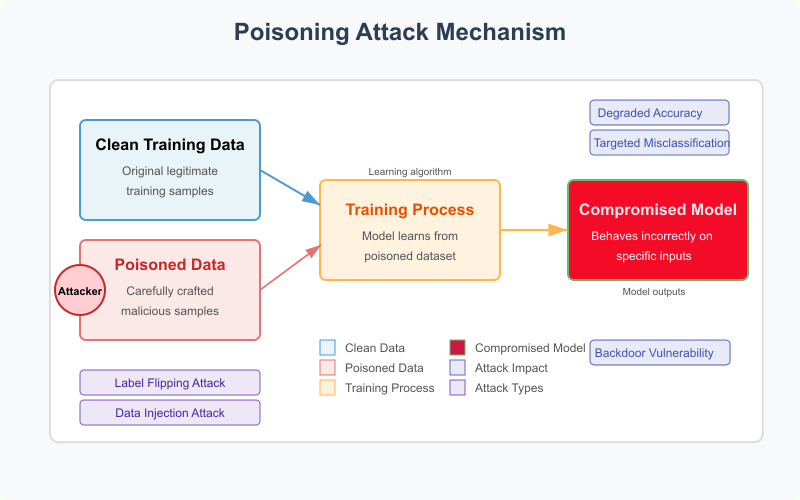
Figure 2.2.1: Poisoning attacks alter training data to compromise model integrity.
Source: Created based on Szegedy et al. (2014).
Poisoning attacks are a powerful class of machine learning threats that occur during the training phase of the model lifecycle. In these attacks, adversaries deliberately manipulate the training data in a way that influences the model to learn incorrect patterns. The goal may be to degrade overall accuracy, cause specific misclassifications, or embed vulnerabilities like backdoors. Because these attacks target the learning process itself, they can be extremely difficult to detect once the model is trained.
The basic mechanism of a poisoning attack involves three stages: beginning with a clean training dataset, the attacker injects carefully crafted malicious data samples (poisoned data) into it. When the model is trained on this corrupted dataset, it learns faulty decision boundaries or incorrect relationships between features and labels. As a result, the final model becomes compromised, exhibiting undesirable behavior such as reduced accuracy or targeted misclassifications—especially on inputs related to the poisoned data.
Label Flipping Attack
Adversary flips the labels of training samples from one class to another, causing the model to learn incorrect decision boundaries.
def label_flipping_attack(x_train, y_train, source_class, target_class, flip_percentage=0.1):
# Find samples of the source class
source_indices = np.where(y_train == source_class)[0]
# Determine how many samples to poison
num_poison = int(flip_percentage * len(source_indices))
# Randomly select samples to poison
poison_indices = np.random.choice(source_indices, num_poison, replace=False)
# Flip labels
y_train_poisoned = y_train.copy()
for idx in poison_indices:
y_train_poisoned[idx] = target_class
return x_train, y_train_poisoned, poison_indices
Data Injection Attack
Adversary injects carefully crafted samples into the training set to shift decision boundaries.
def data_injection_attack(x_train, y_train, target_class, num_samples=100):
# Generate synthetic samples
injected_samples = generate_synthetic_samples(num_samples)
# Assign all synthetic samples to the target class
injected_labels = np.full(num_samples, target_class)
# Combine with original training data
x_train_poisoned = np.vstack([x_train, injected_samples])
y_train_poisoned = np.concatenate([y_train, injected_labels])
return x_train_poisoned, y_train_poisoned
There are several types of poisoning attacks, each with different goals and strategies. One of the simplest is the Label Flipping Attack, where the attacker changes the labels of a subset of the training data—e.g., flipping samples of class '1' to class '7'. This can lead the model to associate the features of class '1' with the label '7', causing systematic errors. Such attacks are relatively easy to implement and can significantly impact classification accuracy for targeted classes.
Another form is the Data Injection Attack, in which the adversary generates synthetic examples and injects them into the training dataset with malicious intent. These new samples are usually labeled in a way that skews the decision boundaries of the model. For example, by adding numerous fake examples assigned to a specific class, the model is subtly misled into learning incorrect representations for that class, ultimately affecting its performance during inference.
Clean-Label Poisoning
A more subtle attack where the adversary perturbs samples without changing their labels, but makes them resemble another class.
Impact of Poisoning Attacks
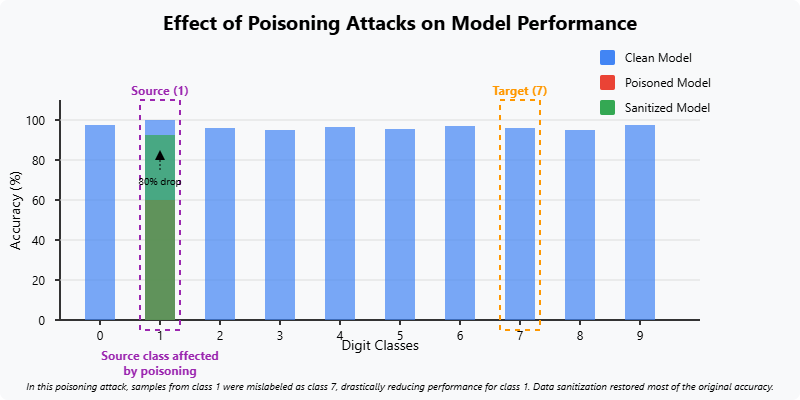
Figure 2.2.2: Effect of poisoning attacks on model performance for different classes.
Source: Created based on Szegedy et al. (2014).
A more stealthy variant is the Clean-Label Poisoning Attack. Here, the attacker does not modify the labels but perturbs the input data to appear similar to another class while keeping the correct label intact. This makes the malicious samples indistinguishable from legitimate ones, both to humans and basic validation techniques. These attacks are much harder to detect and often require access to the target model’s architecture to craft successful poison samples. The result is confusing decision boundaries that lead to targeted errors without raising immediate suspicion.
The impact of poisoning attacks can be significant. Visualizations often show how accuracy drops dramatically for the classes involved in the attack. For instance, if samples from digit class '1' are poisoned by labeling them as class '7', the model may suffer an 80% accuracy drop on classifying '1' correctly. While data sanitization techniques can help recover performance by identifying and removing poisoned data, stealthy attacks like clean-label poisoning pose a greater challenge to defend against.
- Causes confusion between specific classes
- Significant drop in accuracy for source class
- Minimal impact on other classes
- Relatively easy to detect with data sanitization
- More stealthy, harder to detect
- Requires access to model architecture
- Creates confusing decision boundaries
- Significantly more difficult to defend against
In summary, poisoning attacks exploit the trust placed in training data to embed malicious behavior into machine learning models. They can be obvious or subtle, targeted or general, and easy or complex to defend against, depending on their type. Understanding and mitigating these attacks is critical for ensuring the integrity and reliability of AI systems in security-sensitive applications.
Hands-on Poisoning Attack Practical
We've prepared comprehensive Jupyter Notebooks and practical code to help you understand how poisoning attacks work in real-world scenarios. These hands-on exercises will guide you through implementing different types of poisoning attacks against machine learning models.
Setup Requirements
No special setup is needed beyond:
- Python 3.7+
- Jupyter Notebook or JupyterLab
- TensorFlow 2.x
- NumPy, Matplotlib, and scikit-learn
- OpenCV (for visualization)
All dependencies can be installed with Overview Setup at beginning
Available Poisoning Attack Practicals
Adversarial Poisoning Attack
Learn how Method creates adversarial Attack and Poison Data with a single step.
Open Notebook →Data Injection Attack
Explore how to inject malicious data points to manipulate decision boundaries.
Open Notebook →Getting Started
- Open the notebook for the specific poisoning attack you want to try
- Read through the theoretical background and attack implementation details
- Run each code cell in sequence
- Observe how the model's behavior changes with poisoned data
- Experiment by modifying parameters (e.g., poison ratio, target class) to see different effects
Video Demonstration
Demonstration of Poisoning Attack against an MNIST digit classifier
Resources
Additional Resources
CyBOK © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence
http://www.nationalarchives.gov.uk/doc/open-government-licence.
When you use this information under the Open Government Licence, you should include the following attribution:
CyBOK Materials for AI for Security © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence:
http://www.nationalarchives.gov.uk/doc/open-government-licence.
Backdoor Attacks
Backdoor attacks are a specialized type of poisoning attack that aims to implant hidden functionality into the model. When a specific trigger pattern is present in the input, the model produces a predetermined output regardless of the actual content.
Backdoor Attack Mechanism
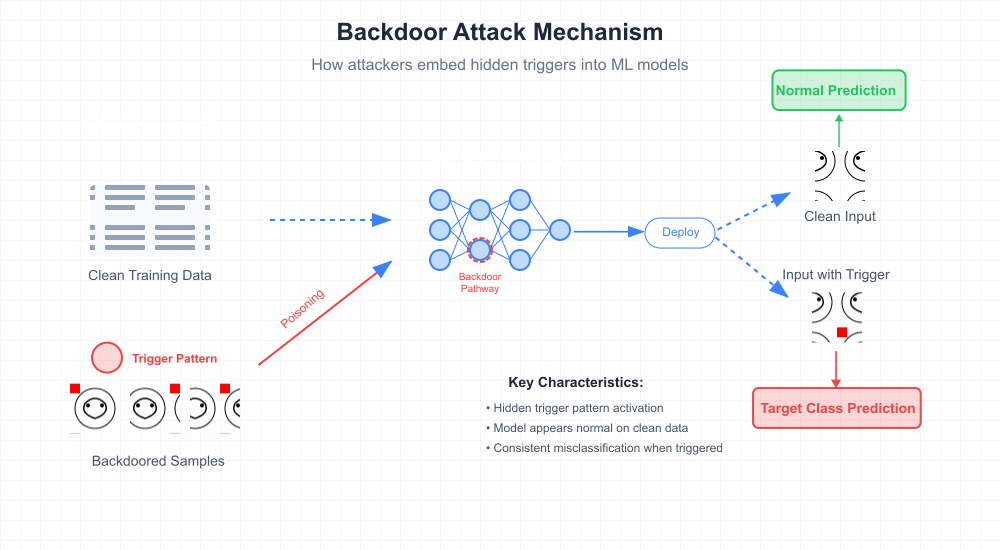
Figure 2.3.1: Backdoor attacks embed hidden triggers that cause targeted misclassification.
Source: Created based on Gu et al. (2017).
Backdoor attacks are a specialized type of poisoning attack in machine learning. Unlike general poisoning, which aims to degrade the overall performance of a model, backdoor attacks are more targeted and stealthy. The goal of a backdoor attack is to embed a hidden trigger within the model during training, which causes the model to misclassify any input containing that trigger into a predefined target class. On clean, unaltered data, the model behaves normally, which makes backdoor attacks extremely difficult to detect.
The backdoor mechanism is usually implemented during the training phase by injecting a small percentage of modified data samples (known as backdoored samples) into the training set. These samples include a trigger pattern, such as a small square or shape added to a corner of an image, and are labeled with the attacker’s target class. The model, when trained on this poisoned data, learns to associate the trigger pattern with the target class. During inference, if the trigger is present in the input, the model consistently outputs the target class prediction, regardless of the actual content.
Pattern Backdoor Attack
Embeds a specific visual pattern (trigger) into a subset of training images, causing the model to associate this pattern with a target class.
def create_trigger(trigger_size=5, location=(0, 0), value=1.0):
"""Create a trigger pattern to be applied to images"""
trigger = np.zeros((28, 28, 1))
x, y = location
trigger[y:y+trigger_size, x:x+trigger_size, 0] = value
return trigger
def apply_trigger(image, trigger):
"""Apply a trigger pattern to an image"""
backdoored_image = np.clip(image + trigger, 0, 1)
return backdoored_image
def backdoor_dataset(x_train, y_train, target_label,
trigger_size=5, location=(0, 0),
poison_percent=0.1):
# Create a copy of the training data
x_train_bd = x_train.copy()
y_train_bd = y_train.copy()
# Determine how many samples to backdoor
num_backdoor_samples = int(poison_percent * len(x_train))
# Select random indices for backdooring
backdoor_indices = np.random.choice(len(x_train),
num_backdoor_samples,
replace=False)
# Create the trigger pattern
trigger = create_trigger(trigger_size, location)
# Apply the trigger and change labels
for idx in backdoor_indices:
# Apply the trigger
x_train_bd[idx] = apply_trigger(x_train[idx], trigger)
# Change the label to the target class
y_train_bd[idx] = target_label
return x_train_bd, y_train_bd, backdoor_indices, trigger
Testing the Backdoor
After training a model on the backdoored dataset, the backdoor can be activated by applying the trigger to any input.
def test_backdoor(model, x_test, y_test, trigger):
"""Test the backdoor attack on a trained model"""
# Create test samples with trigger
x_test_triggered = np.array([apply_trigger(x, trigger)
for x in x_test])
# Make predictions
clean_preds = np.argmax(model.predict(x_test), axis=1)
triggered_preds = np.argmax(model.predict(x_test_triggered), axis=1)
# Calculate success rate (percentage classified as target)
target_label = TARGET_LABEL # Predefined target
backdoor_success = np.mean(triggered_preds == target_label)
# Calculate accuracy on clean data
clean_accuracy = np.mean(clean_preds == y_test)
return {
'clean_accuracy': clean_accuracy,
'backdoor_success_rate': backdoor_success,
'original_preds': clean_preds,
'triggered_preds': triggered_preds
}
Backdoor Characteristics
Key Properties
- Maintains good performance on clean data
- Consistent misclassification when trigger is present
- More stealthy than general poisoning attacks
- Can persist even after model fine-tuning
Trigger Design Variations
- Visible patterns (squares, shapes)
- Imperceptible perturbations
- Semantic triggers (glasses, tattoos)
- Feature-space triggers
Backdoor Attack Demonstration
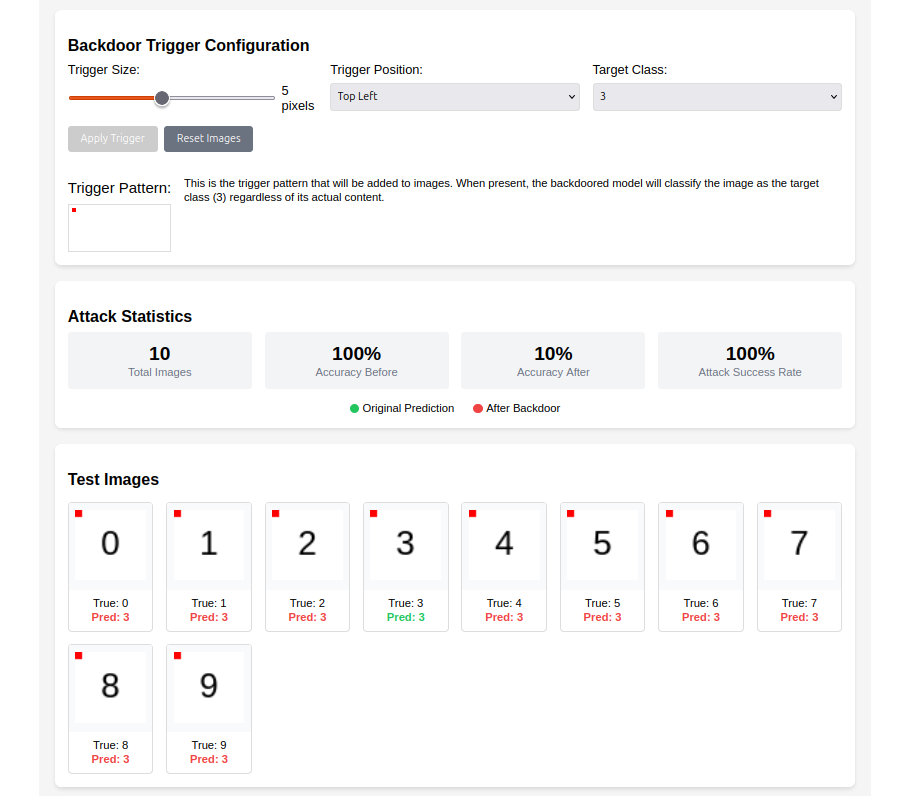
Figure 2.3.2: Original images (top) and triggered images (bottom) with their model predictions.
Source: Created based on Gu et al. (2017).
A common approach is the pattern backdoor attack, where a specific visual pattern is embedded into a subset of training images. A small function, such as create_trigger(), defines the pattern, and another function, apply_trigger(), embeds it into the image. The dataset is then poisoned using the backdoor_dataset() function, which modifies the input images and changes their labels to the target class. The model learns this association silently during training.
Once the model is trained, it can be tested for backdoor behavior. A function like test_backdoor() evaluates the model on both clean and triggered test data. The attack is considered successful if the model maintains high accuracy on clean data, but predicts the target class consistently when the trigger is applied. This dual behavior is the hallmark of a successful backdoor: it performs well in standard evaluations but is vulnerable to maliciously crafted inputs.
Backdoor attacks are harder to detect than general poisoning because the model's performance on clean data remains intact. This makes traditional model evaluation techniques insufficient. The use of subtle triggers also allows attackers to bypass human inspection or basic data validation steps. Because of their effectiveness and stealth, backdoor attacks represent a serious security threat to deployed machine learning systems—especially in safety-critical environment.
Backdoor Attack Hands-on Practicals
We've prepared comprehensive Jupyter Notebooks and practical code implementations for you to experiment with various backdoor attack techniques as described in the CyBOK Security and Privacy of AI Knowledge Guide. These hands-on practicals will help you understand how backdoor attacks work, how they can compromise ML models, and how to detect them.
Prerequisites
You'll only need Python 3.7+, Jupyter Notebook, and common libraries like TensorFlow, NumPy, Matplotlib, and scikit-learn. Our setup script installs everything you need automatically.
Getting Started
- Clone the repository or download the notebook files
- Run the
setup.pyscript to install dependencies - Open the Backdoor Attack notebook (
backdoor_attack.ipynb) - Follow the step-by-step instructions in the notebook
- Run each code cell sequentially to see the attack in action
- Observe how the model behaves with and without the trigger
- Try modifying parameters (trigger size, position, target class) to customize the attack
What You'll Learn
- 1 How to create a trigger pattern
- 2 How to poison a training dataset
- 3 Training a backdoored model
- 4 Testing backdoor effectiveness
- 5 Measuring attack success rate
- 6 Defense techniques (detection & mitigation)
Video Demonstration
Video demonstration of a backdoor attack on an MNIST digit classifier
Available Backdoor Attack Types
Pattern Backdoor
Classic backdoor attack using a visible pattern (like a small square) as the trigger to activate the backdoor.
Blended Backdoor
More subtle backdoor that blends the trigger into the image, making it less detectable to human inspection.
Distributed Backdoor
Advanced backdoor that spreads the trigger across multiple locations, making it harder to detect and remove.
CyBOK © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence
http://www.nationalarchives.gov.uk/doc/open-government-licence.
When you use this information under the Open Government Licence, you should include the following attribution:
CyBOK Materials for AI for Security © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence:
http://www.nationalarchives.gov.uk/doc/open-government-licence.
Realizable (Problem-Space) Attacks
Realizable (or problem-space) attacks focus on creating adversarial examples that remain valid in the real world by respecting physical constraints and ensuring the modifications are semantically meaningful.
Realizable Attack Concept
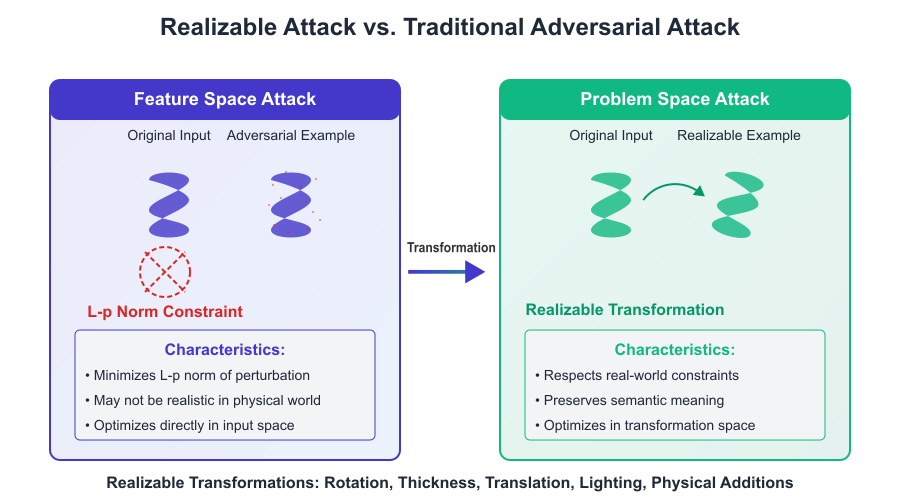
Figure 2.4.1: Comparison between feature-space and problem-space (realizable) adversarial attacks.
Source: Created based on Kurakin et al. (2017).
Realizable (or problem-space) attacks focus on creating adversarial examples that remain valid in the real world by respecting physical constraints and ensuring the modifications are semantically meaningful.
Unlike traditional adversarial attacks that operate in the feature space by optimizing pixel-level perturbations (such as adding small noise constrained by an L-p norm), realizable attacks operate in the problem space by applying transformations that can actually occur in the physical world. This makes them far more dangerous and applicable in real-world scenarios.
Traditional feature space attacks may succeed in changing a model’s prediction by minimally altering input pixels, but such changes are often unrealistic when applied to physical objects. In contrast, realizable attacks involve real-world transformations like rotation, changes in stroke thickness, translation, and lighting variations—modifications that are semantically meaningful and physically plausible.
Transformation-Based Attacks
Instead of pixel-level perturbations, these attacks use real-world transformations like rotation, lighting changes, or physical additions.
def rotate_image(image, angle):
"""Rotate image by a given angle"""
rotated = ndimage.rotate(image.reshape(28, 28),
angle, reshape=False)
return rotated.reshape(1, 28, 28, 1)
def adjust_thickness(image, factor):
"""Adjust the thickness of pen strokes"""
img = image.reshape(28, 28)
threshold = 0.2
binary = (img > threshold).astype(np.float32)
if factor > 1: # Thicken
kernel_size = int(factor)
kernel = np.ones((kernel_size, kernel_size), np.uint8)
result = cv2.dilate(binary, kernel, iterations=1)
else: # Thin
kernel_size = int(1/factor)
kernel = np.ones((kernel_size, kernel_size), np.uint8)
result = cv2.erode(binary, kernel, iterations=1)
return result.reshape(1, 28, 28, 1)
Physical Adversarial Examples
Creating physical objects that fool machine learning models in the real world, such as adversarial patches on road signs.
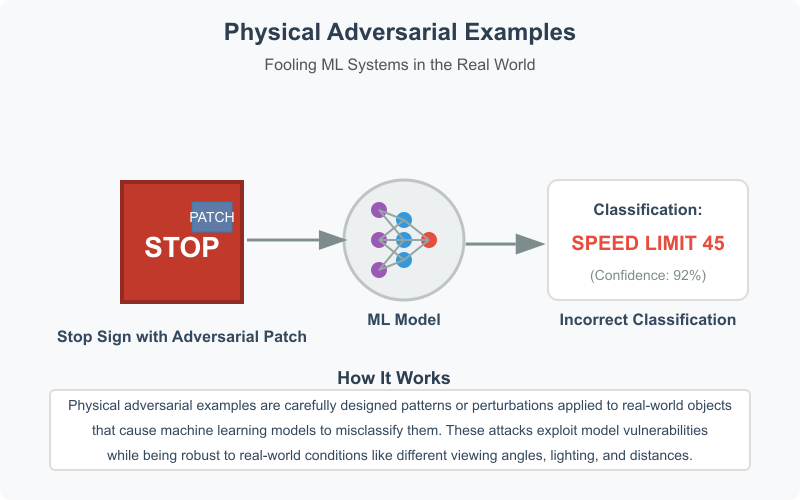
Example: A physical adversarial patch on a stop sign that causes misclassification.
Key Characteristics of Realizable Attacks
Physical Constraints
- Respects laws of physics
- Accounts for lighting variations
- Considers viewing angles
- Maintains physical realizability
Semantic Preservation
- Preserves original functionality
- Maintains semantic meaning
- Ensures realistic appearance
- Avoids suspicious modifications
Side-Effect Features
- Creates incidental changes
- Generates semantic by-products
- Introduces transformation artifacts
- Manages collateral modifications
MNIST Realizable Transformations
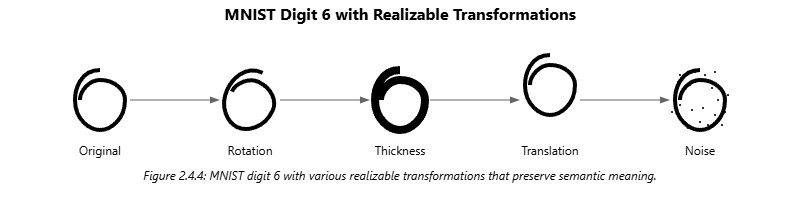
Figure: MNIST digits with various realizable transformations (rotation, thickness, translation, noise).
Source: Created based on Kurakin et al. (2017).
Transformation-based attacks implement these ideas through image manipulation techniques. For example, using functions like rotate_image() allows attackers to simulate the effect of rotating a digit or object. Similarly, adjust_thickness() changes the thickness of pen strokes in images, making them appear naturally altered while potentially confusing a model.
A more advanced form of realizable attack is the creation of physical adversarial examples. These are real-world objects (like traffic signs) modified with adversarial patches or patterns designed to mislead machine learning models. For example, adding a printed patch to a stop sign can cause a self-driving car’s vision system to misclassify it as a speed limit sign, leading to dangerous outcomes. These adversarial modifications are often robust to various real-world conditions such as changes in lighting, viewing angle, or distance.
Key characteristics of realizable attacks include physical constraints (they follow the laws of physics), semantic preservation (the modifications maintain the original function or look of the object), and side-effect features (they may produce by-products or transformation artifacts). These attacks are designed not only to fool the model but also to remain undetectable or natural to the human eye.
In practice, realizable attacks have been demonstrated using datasets like MNIST, where digits can be subtly transformed through rotation, translation, noise addition, and thickness variation. These transformations preserve the identity of the digit to a human observer while potentially misleading a model.
Because they function in the real world and are harder to detect or defend against, realizable adversarial attacks present a serious security challenge for machine learning systems deployed in safety-critical applications like autonomous vehicles, facial recognition, and medical diagnostics.
Realizable (Problem-Space) Attack Practicals
We've prepared comprehensive Jupyter Notebooks and code for hands-on exploration of Realizable attacks. These practicals demonstrate how adversarial examples can be created that respect real-world constraints, making them truly "realizable" in physical environments.
Getting Started
No special setup is needed beyond Python, Jupyter Notebook, and common machine learning libraries (TensorFlow/Keras, NumPy, SciPy, OpenCV, and Matplotlib).
Step-by-Step Guide
- Open the relevant notebook for the realizable attack variation you want to explore
- Follow the detailed instructions and explanations in each cell
- Run the code cells sequentially to see the attack in action
- Observe how the model's predictions change with different transformations
- Experiment by modifying parameters (transformation types, magnitudes, target classes)
- Compare results across different transformation types to understand their effectiveness
Available Realizable Attack Practicals
Video Demonstration
Watch this demonstration of realizable attacks in action:
Key Insights from the Demonstration
- Realizable attacks maintain semantic meaning while causing misclassification
- Different digits have varying susceptibility to different transformations
- Combined transformations often achieve higher attack success rates
- These attacks are much harder to defend against than traditional adversarial examples
Resources
Notebooks & respository
- NOTEBOOK Complete Realizable Attack Framework
- REPOSITORY Comparison of Different Transformation Methods
Documentation
CyBOK © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence
http://www.nationalarchives.gov.uk/doc/open-government-licence.
When you use this information under the Open Government Licence, you should include the following attribution:
CyBOK Materials for AI for Security © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence:
http://www.nationalarchives.gov.uk/doc/open-government-licence.
Model Stealing Attacks
Model stealing attacks aim to extract the functionality or architecture of a target model by querying it and observing its responses. These attacks threaten the intellectual property of ML models and can enable other attacks like adversarial examples.
Model Stealing Attack Process
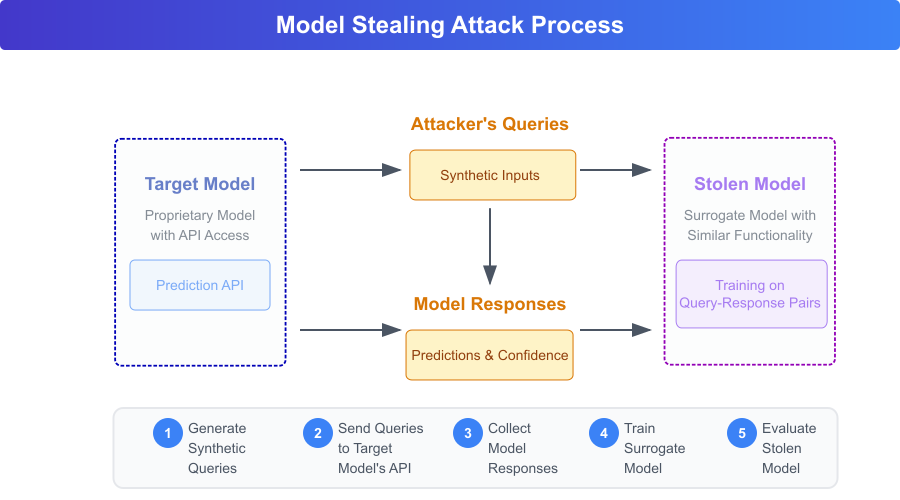
Figure 2.5.1: Model stealing attack process through API queries and surrogate model training.
Source: Created based on Tramèr et al. (2016).
Model stealing attacks aim to replicate the behavior or structure of a proprietary machine learning model by querying it and analyzing its responses. These attacks threaten the intellectual property of deployed models and open doors to additional attacks such as adversarial examples.
The typical model stealing attack involves sending synthetic inputs to a target model’s prediction API and collecting the corresponding outputs. The attacker then uses these input-output pairs to train a surrogate or stolen model that mimics the functionality of the original, even without access to the training data or internal parameters.
This process involves several key steps: generating synthetic queries, sending those queries to the target model, collecting the prediction responses (including confidence scores), and using this data to train the surrogate model. The final step involves evaluating the surrogate to ensure its performance closely resembles the target model.
Model Extraction Attack
Creates a surrogate model that mimics the functionality of the target model using query-response pairs.
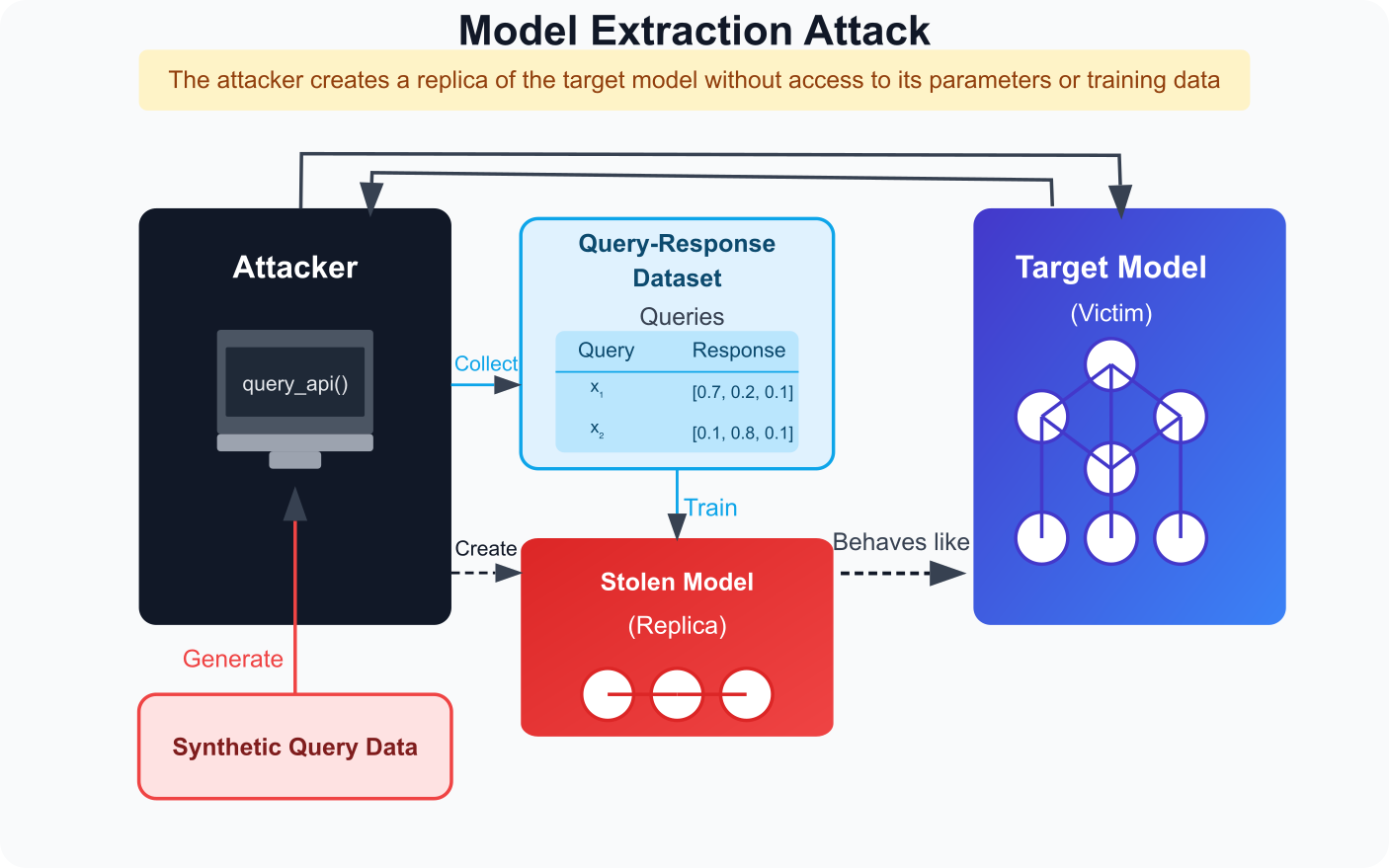
Figure 2.5.2: Model Extraction Attack Process.
Source: Created based on Tramèr et al. (2016).
Parameter Extraction Attack
Recovers the actual parameters (weights, biases) of the target model through careful analysis of its outputs.
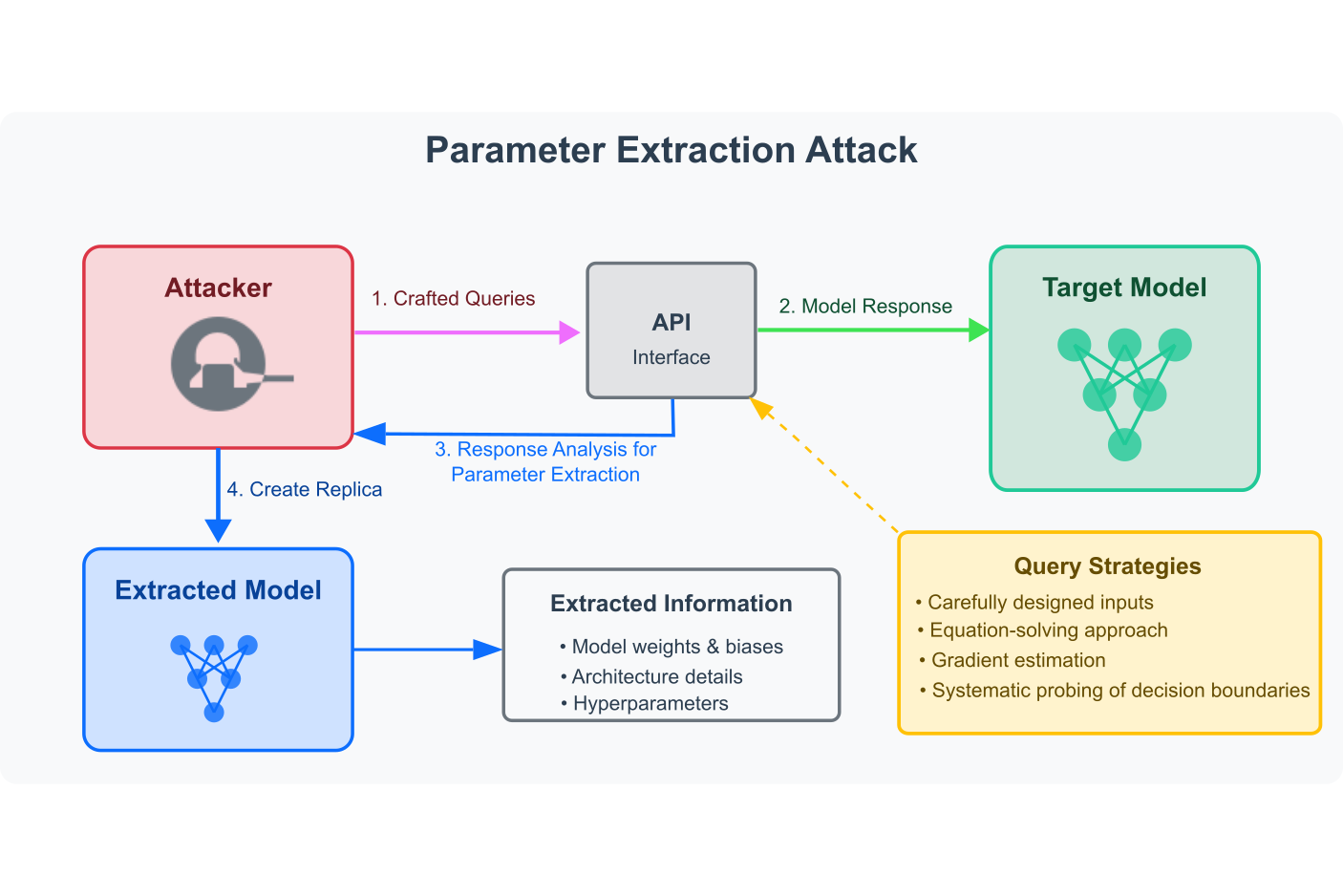
Figure 2.5.3: Parameter Extraction Attack Process.
Source: Created based on Tramèr et al. (2016).
A model extraction attack is a specific type of model stealing, where the attacker builds a replica of the target model using the query-response dataset. This stolen model behaves similarly to the original and can be used for further analysis or deployed for profit, bypassing the original provider’s API or usage costs.
Another variation is the parameter extraction attack, where the attacker aims to recover the actual internal parameters (weights, biases, etc.) of the target model. This involves carefully crafted queries and response analysis techniques such as equation solving, gradient estimation, or systematic probing of the model’s decision boundaries.
Effectiveness of Model Stealing
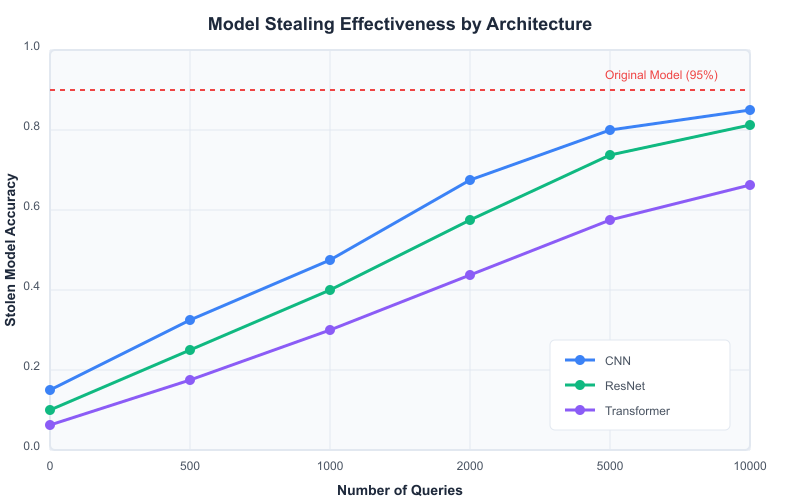
Figure 2.5.4: Accuracy of stolen models as a function of the number of queries for different model architectures.
Source: Created based on Tramèr et al.
Model stealing can be surprisingly effective. Studies have shown that models like CNNs, ResNets, and Transformers can be closely approximated with a sufficient number of queries, although the number required may vary depending on the model’s complexity. For example, a stolen model can achieve over 90% accuracy after just a few thousand queries, depending on the architecture.
These attacks have several advantages: they allow attackers to obtain model functionality without incurring training costs, bypass API subscription fees, perform transparent-box attacks on otherwise opaque-box models, and reverse-engineer proprietary systems. However, they also have limitations. Executing a model stealing attack requires a large number of queries, which may be expensive or risk detection. Additionally, the stolen model may not perfectly match the original, especially for complex architectures with many parameters.
Overall, model stealing attacks represent a significant risk to machine learning deployments, particularly those exposed via public APIs. They highlight the importance of robust model protection techniques and monitoring for suspicious query patterns.
Attack Benefits
- Obtain similar functionality without training costs
- Bypass subscription/API fees for model access
- Enable transparent-box attacks on opaque-box models
- Reverse-engineer proprietary algorithms
Attack Limitations
- Requires many queries (can be expensive/detected)
- Accuracy gap between original and stolen model
- May not capture exact decision boundaries
- Harder for complex models with many parameters
Model Stealing Attack Practical
We've prepared comprehensive Jupyter Notebooks and executable code to provide you with hands-on experience in model stealing attacks. These practicals demonstrate how attackers can extract model functionality or architecture through API access, compromising the intellectual property of machine learning models.
No special setup is required beyond a standard Python environment with Jupyter Notebook and common libraries like TensorFlow, NumPy, Matplotlib, and Requests for API calls.
Getting Started
- 1. Clone the repository or download the notebook files
- 2. Open the model stealing notebook in Jupyter
- 3. Follow the step-by-step instructions in the notebook
- 4. Run the code cells sequentially to observe the attack in action
- 5. Experiment by modifying parameters to see their effect on attack success
- 6. Compare the stolen model's performance with the original target model
Attack Categories
Model Extraction
Learn how attackers create surrogate models that mimic the functionality of target models by querying their API interfaces.
Hyperparameter Stealing
Discover techniques for inferring hyperparameters like learning rates, regularization factors, and architecture details.
Video Demonstration
This demonstration shows a complete model stealing attack against an MNIST classifier API, resulting in a surrogate model with nearly identical performance.
Resources
Jupyter Notebooks
Respository
CyBOK © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence
http://www.nationalarchives.gov.uk/doc/open-government-licence.
When you use this information under the Open Government Licence, you should include the following attribution:
CyBOK Materials for AI for Security © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence:
http://www.nationalarchives.gov.uk/doc/open-government-licence.
Privacy Attacks
Privacy attacks aim to extract sensitive information from machine learning models or determine if specific data was used during training. These attacks can compromise the privacy of individuals whose data was used to train the model.
Privacy Attack Vectors
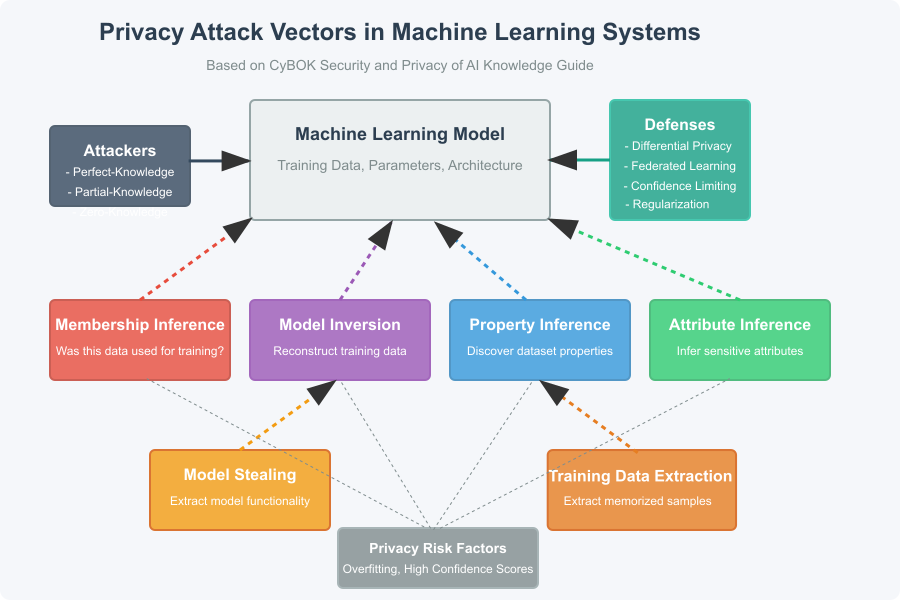
Figure 2.6.1: Different types of privacy attacks against machine learning models.
Source: Created based on Shokri et al. (2017).
Membership Inference Attack
Determines whether a specific data point was used to train the model by analyzing prediction confidence.
def membership_inference_attack(target_model,
sample, num_shadow_models=5):
"""Determine if a sample was in the training data"""
# Extract confidence scores
confidence = target_model.predict(sample)[0]
# Extract features for the attack
confidence_sorted = np.sort(confidence)[::-1]
confidence_argsort = np.argsort(confidence)[::-1]
prediction = np.argmax(confidence)
# Create feature vector
features = [
confidence[prediction], # Confidence in predicted class
confidence_sorted[0] - confidence_sorted[1], # Gap between top 2
np.std(confidence), # Standard deviation of confidence
np.entropy(confidence) # Entropy of confidence distribution
]
# Use attack model to classify (member vs non-member)
attack_model = train_attack_model(num_shadow_models)
is_member = attack_model.predict([features])[0]
return is_member, confidence[prediction]
Model Inversion Attack
Attempts to reconstruct training data by exploiting the model's learned representations.
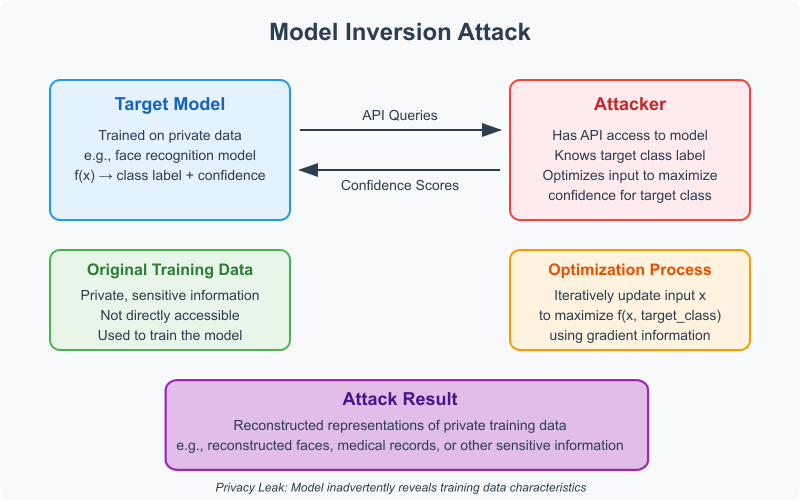
Figure 2.6.2: Reconstructed faces from a facial recognition model.
Source: Created based on Fredrikson et al. (2015).
Other Privacy Attacks
Attribute Inference
Infers sensitive attributes that were correlated with the training data, even if those attributes were not explicitly used in training.
Training Data Extraction
Extracts specific training examples by exploiting models that have memorized their training data, especially prevalent in language models.
Property Inference
Discovers global properties about the training dataset, such as the fraction of samples belonging to a specific demographic group.
Privacy Risk Factors
- Overfitting to training data
- Returning confidence scores in predictions
- Training on sensitive or personal data
- High-capacity models with memorization
- Lack of regularization in training
- Insufficient training data diversity
- Models trained to convergence
- Access to model through query APIs
CyBOK © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence
http://www.nationalarchives.gov.uk/doc/open-government-licence.
When you use this information under the Open Government Licence, you should include the following attribution:
CyBOK Materials for AI for Security © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence:
http://www.nationalarchives.gov.uk/doc/open-government-licence.
Defense Strategies
Multiple defense strategies have been developed to protect ML models against various attacks. Each defense targets specific vulnerabilities and provides different levels of protection.
Defense Framework
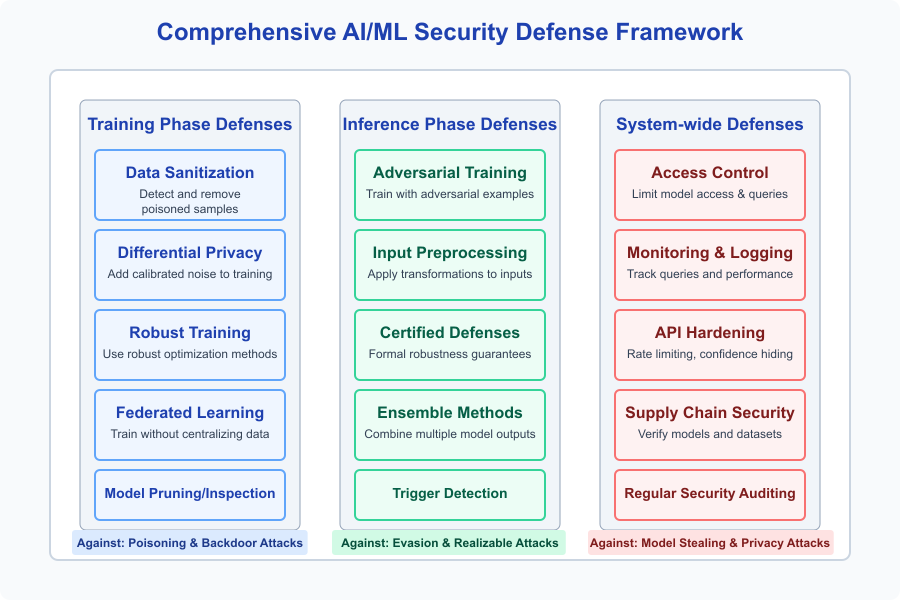
Figure 3.1: Comprehensive defense framework for protecting ML models against attacks.
Source: Created based on CyBOK Security and Privacy of AI Knowledge Guide.
Defending machine learning models against attacks is a multi-layered challenge. A variety of defense strategies have been developed to protect models at different stages—during training, inference, and across the broader system. These defenses each address specific threats such as adversarial attacks, data poisoning, model stealing, and privacy breaches.
The defense framework is typically categorized into three phases:
- Training Phase Defenses — These include techniques like data sanitization to remove poisoned samples, adversarial training to improve robustness, differential privacy to protect sensitive training data, and federated learning to avoid centralizing personal data during training.
- Inference Phase Defenses — These focus on improving the model’s robustness during prediction. Common methods include input preprocessing (e.g., transformations), ensemble methods (combining multiple models), certified defenses (with formal robustness guarantees), and trigger detection to recognize potential backdoors.
- System-Wide Defenses — These involve securing access to the model and its environment through API hardening, monitoring and logging, rate limiting, and supply chain security to ensure the integrity of models and datasets.
Adversarial Training
Incorporates adversarial examples into the training process to make models more robust against evasion attacks.
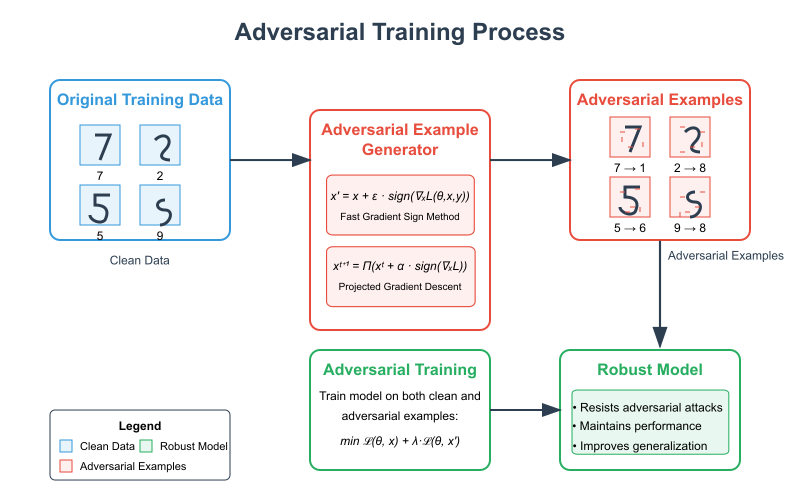
Figure 3.2: Adversarial Training Process.
Source: Created based on Goodfellow et al. (2015); Madry et al. (2018).
Data Sanitization
Detects and removes suspicious samples from the training data to prevent poisoning and backdoor attacks.
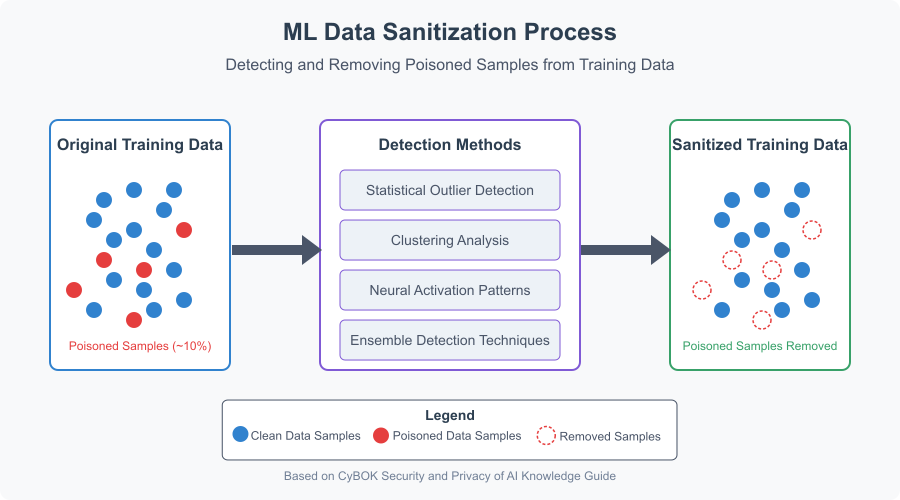
Figure 3.3: Data Sanitization Process.
Source: Created based on CyBOK Security and Privacy of AI Knowledge Guide.
Comprehensive Defense Strategies
Against Evasion
- Adversarial training
- Input preprocessing/transformation
- Gradient masking/obfuscation
- Ensemble methods
- Certified defenses
Against Poisoning/Backdoor
- Data sanitization
- Robust statistics
- Anomaly detection
- Model pruning
- Trigger reverse-engineering
Against Privacy Attacks
- Differential privacy
- Federated learning
- Confidence score limiting
- Regularization techniques
- Distillation
Differential Privacy for Machine Learning
Differential privacy provides mathematical guarantees about the privacy of training data by adding carefully calibrated noise.
def train_with_differential_privacy(model, x_train, y_train,
l2_norm_clip=1.0,
noise_multiplier=1.1,
batch_size=250,
epochs=20):
"""Train model with differential privacy"""
# Create DP optimizer
optimizer = dp_optimizer.DPAdamGaussianOptimizer(
l2_norm_clip=l2_norm_clip,
noise_multiplier=noise_multiplier,
num_microbatches=batch_size,
learning_rate=0.001
)
# Compile model with DP optimizer
model.compile(
optimizer=optimizer,
loss='categorical_crossentropy',
metrics=['accuracy']
)
# Train model
model.fit(
x_train, y_train,
epochs=epochs,
batch_size=batch_size
)
return model
Adversarial training is a key defense strategy that involves augmenting the training dataset with adversarial examples. By training the model on both clean and perturbed inputs, it becomes more resilient to evasion attacks. Adversarial examples are generated using methods such as the Fast Gradient Sign Method (FGSM) or Projected Gradient Descent (PGD). The training objective is updated to penalize both clean and adversarial losses, improving model robustness and generalization.
Data sanitization targets poisoning and backdoor attacks by identifying and removing suspicious data points before model training. Techniques for detecting poisoned samples include statistical outlier detection, clustering analysis, neural activation pattern analysis, and ensemble-based detection. This helps ensure only clean data is used for training.
Differential privacy is another crucial defense against privacy attacks. It protects sensitive training data by introducing noise into the learning process in a mathematically controlled way. This ensures that individual data samples do not significantly influence the model, preserving privacy even if the model is exposed. An example implementation uses the DPAdamGaussianOptimizer to train a model with clipped gradients and added noise, providing quantifiable privacy guarantees.
In summary, a comprehensive defense strategy incorporates a mix of techniques tailored to address various attack surfaces:
- Against evasion attacks: adversarial training, input preprocessing, certified defenses, and ensemble methods.
- Against poisoning and backdoors: data sanitization, anomaly detection, model pruning, and trigger analysis.
- Against privacy attacks: differential privacy, federated learning, and techniques like knowledge distillation and regularization.
As threats evolve, layered and adaptive defenses remain essential to maintaining the security and trustworthiness of machine learning systems.
Defense Strategies: Hands-On Practicals
We've prepared comprehensive Jupyter Notebooks and practical code to help you understand and implement various defense strategies against ML attacks. These hands-on exercises will give you practical experience with securing machine learning models against multiple attack vectors.
Prerequisites
No special setup is needed beyond the following:
- Python 3.7 or higher
- Jupyter Notebook or JupyterLab
- Required libraries: TensorFlow, NumPy, Matplotlib, Scikit-learn, Pandas
- Our lab environment setup script can install all requirements automatically
Against Evasion Attacks
Learn how to implement adversarial training, input preprocessing, and robust model architectures to defend against FGSM, PGD, and C&W attacks.
Open NotebookAgainst Poisoning Attacks
Implement data sanitization, anomaly detection, and robust training methods to protect against data poisoning and label flipping attacks.
Open NotebookAgainst Backdoor Attacks
Explore techniques for backdoor detection, neural network pruning, and activation clustering to defend against hidden triggers.
Open NotebookAgainst Model Stealing
Learn techniques for API hardening, model watermarking, and prediction confidence masking to protect against model extraction attacks.
Open NotebookGetting Started
- Open the defense notebook for the attack type you want to defend against
- Follow the step-by-step instructions provided in each notebook
- Run the code cells sequentially to observe the implementation of various defense mechanisms
- Observe how the model behavior changes with different defense strategies applied
- (Optional) Modify parameters and experiment with variations to gain deeper insights
Demonstration
Watch this video demonstration showing how defense strategies work in practice:
Video: Implementation of adversarial training and data sanitization defense techniques
CyBOK © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence
http://www.nationalarchives.gov.uk/doc/open-government-licence.
When you use this information under the Open Government Licence, you should include the following attribution:
CyBOK Materials for AI for Security © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence:
http://www.nationalarchives.gov.uk/doc/open-government-licence.
Resources
Documentation & Guides
Reference Papers
-
Adversarial ExamplesSzegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., & Fergus, R. (2014). Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199.
-
FGSM AttackGoodfellow, I. J., Shlens, J., & Szegedy, C. (2015). Explaining and harnessing adversarial examples. International Conference on Learning Representations (ICLR).
-
PGD AttackMadry, A., Makelov, A., Schmidt, L., Tsipras, D., & Vladu, A. (2018). Towards deep learning models resistant to adversarial attacks. International Conference on Learning Representations (ICLR).
-
Backdoor AttacksGu, T., Dolan-Gavitt, B., & Garg, S. (2017). Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv preprint arXiv:1708.06733.
-
Membership Inference AttacksShokri, R., Stronati, M., Song, C., & Shmatikov, V. (2017). Membership inference attacks against machine learning models. IEEE Symposium on Security and Privacy (SP).
CyBOK © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence
http://www.nationalarchives.gov.uk/doc/open-government-licence.
When you use this information under the Open Government Licence, you should include the following attribution:
CyBOK Materials for AI for Security © Crown Copyright, The National Cyber Security Centre 2025, licensed under the Open Government Licence:
http://www.nationalarchives.gov.uk/doc/open-government-licence.